New chapter titled “DC-Image for Real Time Compressed Video Matching” is published in Springer Transactions on Engineering Technologies 2014 .
Well done and congratulations to Saddam Bekhet.


Active researcher on medical imaging and video analysis
New chapter titled “DC-Image for Real Time Compressed Video Matching” is published in Springer Transactions on Engineering Technologies 2014 .
Well done and congratulations to Saddam Bekhet.
Congratulations to Dr Amjad Altadmri for completeing his PhD degree. Amjad received his PhD degree in the formal September Graduation Ceremony at the Lincoln Cathedral.

His PhD titled “Semantic Annotation of Domain-Independent Uncontrolled Videos, Incorporating Visual Similarity and Commonsesne Knowledge Bases”. The work produced a Framework for semantic video annotation. In addition, VisualNet was also produced, which is a semantic Network for Visual-related applications.
The photo shows Dr Amjad Altadmri (Left) with his Director of Studies/Supervisor Dr Amr Ahmed ( right).
A list of publications of Amjad’s PhD are below:
Amjad has also participated, with Amr and other members of the DCAPI group, in various workshops especially the V&L EPSRC Network workshops. They presented sessions and showed posters; see related blog posts:
Congratulations to Saddam Bekhet (PhD Researcher) who achieved the “Best Student Paper Award 2013″ for his conference paper entitled “Video Matching Using DC-image and Local Features ” presented earlier in “World Congress on Engineering 2013“ in London .

Abstract: This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
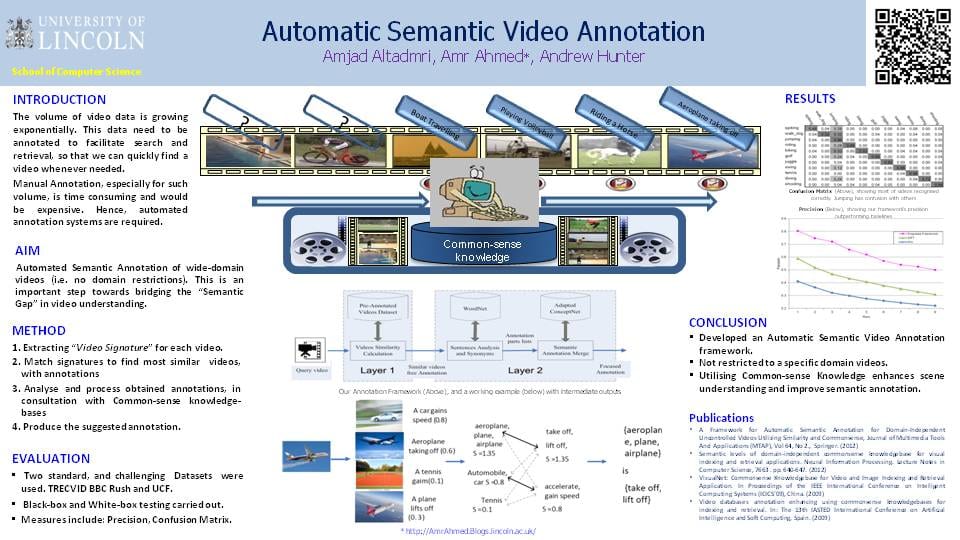
Automatic Semantic Video Annotation
Amjad Altadmri, Amr Ahmed*, Andrew Hunter
(Click Semantic Video Annotation-with Knowledge ” http://amrahmed.blogs.lincoln.ac.uk/files/2013/03/Semantic-Video-Annotation-with-Knowledge.pdf , to download the pdf)
INTRODUCTION
The volume of video data is growing exponentially. This data need to be annotated to facilitate search and retrieval, so that we can quickly find a video whenever needed.
Manual Annotation, especially for such volume, is time consuming and would be expensive. Hence, automated annotation systems are required.
AIM
Automated Semantic Annotation of wide-domain videos (i.e. no domain restrictions). This is an important step towards bridging the “Semantic Gap” in video understanding.
METHOD
EVALUATION
CONCLUSION
New Journal paper accepted for publishing in the Journal of “Multimedia Tools and Applications“.
The paper title is “A Framework for Automatic Semantic Video Annotation utilising Similarity and Commonsense Knowledgebases”
Abstract:
The rapidly increasing quantity of publicly available videos has driven research into developing automatic tools for indexing, rating, searching and retrieval. Textual semantic representations, such as tagging, labelling and annotation, are often important factors in the process of indexing any video, because of their user-friendly way of representing the semantics appropriate for search and retrieval. Ideally, this annotation should be inspired by the human cognitive way of perceiving and of describing videos. The difference between the low-level visual contents and the corresponding human perception is referred to as the ‘semantic gap’. Tackling this gap is even harder in the case of unconstrained videos, mainly due to the lack of any previous information about the analyzed video on the one hand, and the huge amount of generic knowledge required on the other.
This paper introduces a framework for the Automatic Semantic Annotation of unconstrained videos. The proposed framework utilizes two non-domain-specific layers: low-level visual similarity matching, and an annotation analysis that employs commonsense knowledgebases. Commonsense ontology is created by incorporating multiple-structured semantic relationships. Experiments and black-box tests are carried out on standard video databases for
action recognition and video information retrieval. White-box tests examine the performance of the individual intermediate layers of the framework, and the evaluation of the results and the statistical analysis show that integrating visual similarity matching with commonsense semantic relationships provides an effective approach to automated video annotation.
Well done and congratulations to Amjad Altadmri .