Summary: “Object and Action Recognition Assisted by Computational Linguistics”.
The aim of this project is to investigate how computer vision methods such as object and
action recognition may be assisted by computational linguistic models, such as WordNet.
The main challenge of object and action recognition is the scalability of methods from
dealing with a dozen of categories (e.g. PASCAL VOC) to thousands of concepts (e.g.
ImageNet ILSVRC). This project is expected to contribute to the application of automated
visual content annotation and more widely to bridging the semantic gap between
computational approaches of vision and language.
The paper “Compact Signature-based Compressed Video Matching Using Dominant Colour Profiles (DCP)” has been accepted in the ICPR 2014 conference http://www.icpr2014.org/, and will be presented in August 2014, Stockholm, Sweden.
Abstract— This paper presents a technique for efficient and generic matching of compressed video shots, through compact signatures extracted directly without decompression. The compact signature is based on the Dominant Colour Profile (DCP); a sequence of dominant colours extracted and arranged as a sequence of spikes, in analogy to the human retinal representation of a scene. The proposed signature represents a given video shot with ~490 integer values, facilitating for real-time processing to retrieve a maximum set of matching videos. The technique is able to work directly on MPEG compressed videos, without full decompression, as it is utilizing the DC-image as a base for extracting colour features. The DC-image has a highly reduced size, while retaining most of visual aspects, and provides high performance compared to the full I-frame. The experiments and results on various standard datasets show the promising performance, both the accuracy and the efficient computation complexity, of the proposed technique.
Congratulations to Dr Amjad Altadmri for completeing his PhD degree. Amjad received his PhD degree in the formal September Graduation Ceremony at the Lincoln Cathedral.
Amjad Graduation Ceremony – September 2013
His PhD titled “Semantic Annotation of Domain-Independent Uncontrolled Videos, Incorporating Visual Similarity and Commonsesne Knowledge Bases”. The work produced a Framework for semantic video annotation. In addition, VisualNet was also produced, which is a semantic Network for Visual-related applications.
The photo shows Dr Amjad Altadmri (Left) with his Director of Studies/Supervisor Dr Amr Ahmed ( right).
Amjad has also participated, with Amr and other members of the DCAPI group, in various workshops especially the V&L EPSRC Network workshops. They presented sessions and showed posters; see related blog posts:
Congratulations to Saddam Bekhet (PhD Researcher) who achieved the “Best Student Paper Award 2013″ for his conference paper entitled “Video Matching Using DC-image and Local Features ” presented earlier in “World Congress on Engineering 2013“ in London .
Abstract: This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
The paper (titled “Video Matching Using DC-image and Local Features”) was presented by Saddam Bekhet (PhD Rsearcher) in the International Conference of Signal and Image Engineering (ICSIE’13), during the World Congress on Engineering 2013, in London UK.
Abstract:
This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
New Conference paper accepted for publishing in “World Congress on Engineering 2013“.
The paper title is “Video Matching Using DC-image and Local Features ”
Abstract:
This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
(Click Semantic Video Annotation-with Knowledge ” http://amrahmed.blogs.lincoln.ac.uk/files/2013/03/Semantic-Video-Annotation-with-Knowledge.pdf , to download the pdf)
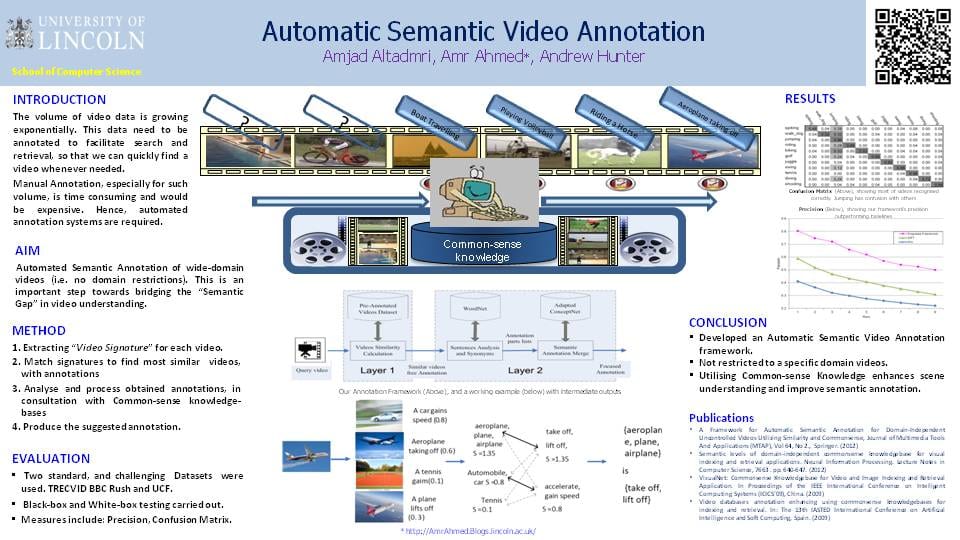
INTRODUCTION
The volume of video data is growing exponentially. This data need to be annotated to facilitate search and retrieval, so that we can quickly find a video whenever needed.
Manual Annotation, especially for such volume, is time consuming and would be expensive. Hence, automated annotation systems are required.
AIM
Automated Semantic Annotation of wide-domain videos (i.e. no domain restrictions). This is an important step towards bridging the “Semantic Gap” in video understanding.
METHOD
1. Extracting “Video Signature” for each video.
2. Match signatures to find most similar videos, with annotations
3. Analyse and process obtained annotations, in consultation with Common-sense knowledge-bases
4. Produce the suggested annotation.
EVALUATION
• Two standard, and challenging Datasets were used. TRECVID BBC Rush and UCF.
• Black-box and White-box testing carried out.
•Measures include: Precision, Confusion Matrix.
CONCLUSION
•Developed an Automatic Semantic Video Annotation framework.
•Not restricted to a specific domain videos.
•Utilising Common-sense Knowledge enhances scene understanding and improve semantic annotation.