

Automatic Semantic Video Annotation
Amjad Altadmri, Amr Ahmed*, Andrew Hunter
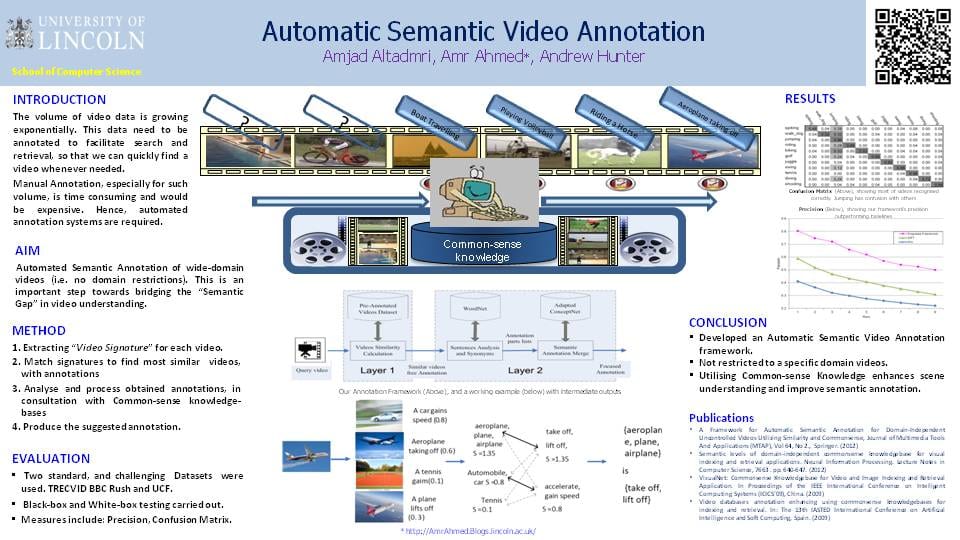
(Click Semantic Video Annotation-with Knowledge ” http://amrahmed.blogs.lincoln.ac.uk/files/2013/03/Semantic-Video-Annotation-with-Knowledge.pdf , to download the pdf)
INTRODUCTION
The volume of video data is growing exponentially. This data need to be annotated to facilitate search and retrieval, so that we can quickly find a video whenever needed.
Manual Annotation, especially for such volume, is time consuming and would be expensive. Hence, automated annotation systems are required.
AIM
Automated Semantic Annotation of wide-domain videos (i.e. no domain restrictions). This is an important step towards bridging the “Semantic Gap” in video understanding.
METHOD
EVALUATION
CONCLUSION
- A framework for automatic semantic video annotation
Altadmri, Amjad and Ahmed, Amr (2013) A framework for automatic semantic video annotation. Multimedia Tools and Applications, 64 (2). ISSN 1380-7501. - Semantic levels of domain-independent commonsense knowledgebase for visual indexing and retrieval applications
Altadmri, Amjad and Ahmed, Amr and Mohtasseb Billah, Haytham (2012) Semantic levels of domain-independent commonsense knowledgebase for visual indexing and retrieval applications. Neural Information Processing. Lecture Notes in Computer Science, 7663 . pp. 640-647. ISSN 0302-9743 - VisualNet: commonsense knowledgebase for video and image indexing and retrieval application
Alabdullah Altadmri, Amjad and Ahmed, Amr (2009) VisualNet: commonsense knowledgebase for video and image indexing and retrieval application. In: IEEE International Conference on Intelligent Computing and Intelligent Systems, 21-22 November 2009, Shanghai, China.. - Automatic semantic video annotation in wide domain videos based on similarity and commonsense knowledgebases
Altadmri, Amjad and Ahmed, Amr (2009) Automatic semantic video annotation in wide domain videos based on similarity and commonsense knowledgebases. In: The IEEE International Conference on Signal and Image Processing Applications (ICSIPA 2009), 18-19th November 2009, Malaysia. - Video databases annotation enhancing using commonsense knowledgebases for indexing and retrieval
Altadmri, Amjad and Ahmed, Amr (2009) Video databases annotation enhancing using commonsense knowledgebases for indexing and retrieval. In: The 13th IASTED International Conference on Artificial Intelligence and Soft Computing., September 7 � 9, 2009, Palma de Mallorca, Spain.