Congratulations to Saddam Bekhet (PhD Researcher) who achieved the “Best Student Paper Award 2013″ for his conference paper entitled “Video Matching Using DC-image and Local Features ” presented earlier in “World Congress on Engineering 2013“ in London .
Abstract: This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
The paper (titled “Video Matching Using DC-image and Local Features”) was presented by Saddam Bekhet (PhD Rsearcher) in the International Conference of Signal and Image Engineering (ICSIE’13), during the World Congress on Engineering 2013, in London UK.
Abstract:
This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
New Conference paper accepted for publishing in “World Congress on Engineering 2013“.
The paper title is “Video Matching Using DC-image and Local Features ”
Abstract:
This paper presents a suggested framework for video matching based on local features extracted from the DC-image of MPEG compressed videos, without decompression. The relevant arguments and supporting evidences are discussed for developing video similarity techniques that works directly on compressed videos, without decompression, and especially utilising small size images. Two experiments are carried to support the above. The first is comparing between the DC-image and I-frame, in terms of matching performance and the corresponding computation complexity. The second experiment compares between using local features and global features in video matching, especially in the compressed domain and with the small size images. The results confirmed that the use of DC-image, despite its highly reduced size, is promising as it produces at least similar (if not better) matching precision, compared to the full I-frame. Also, using SIFT, as a local feature, outperforms precision of most of the standard global features. On the other hand, its computation complexity is relatively higher, but it is still within the real-time margin. There are also various optimisations that can be done to improve this computation complexity.
(Click Semantic Video Annotation-with Knowledge ” http://amrahmed.blogs.lincoln.ac.uk/files/2013/03/Semantic-Video-Annotation-with-Knowledge.pdf , to download the pdf)
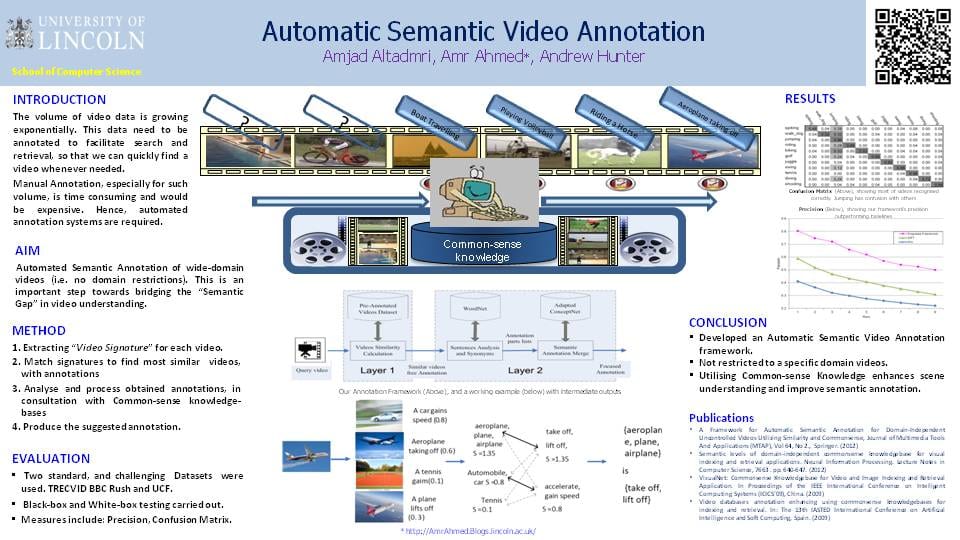
INTRODUCTION
The volume of video data is growing exponentially. This data need to be annotated to facilitate search and retrieval, so that we can quickly find a video whenever needed.
Manual Annotation, especially for such volume, is time consuming and would be expensive. Hence, automated annotation systems are required.
AIM
Automated Semantic Annotation of wide-domain videos (i.e. no domain restrictions). This is an important step towards bridging the “Semantic Gap” in video understanding.
METHOD
1. Extracting “Video Signature” for each video.
2. Match signatures to find most similar videos, with annotations
3. Analyse and process obtained annotations, in consultation with Common-sense knowledge-bases
4. Produce the suggested annotation.
EVALUATION
• Two standard, and challenging Datasets were used. TRECVID BBC Rush and UCF.
• Black-box and White-box testing carried out.
•Measures include: Precision, Confusion Matrix.
CONCLUSION
•Developed an Automatic Semantic Video Annotation framework.
•Not restricted to a specific domain videos.
•Utilising Common-sense Knowledge enhances scene understanding and improve semantic annotation.
Amjad Altadmri has passed his PhD viva, subject to minor amendments, earlier today.
Thesis Title: “Semantic Video Annotation in Domain-Independent Videos Utilising Similarity and Commonsense Knowledgebases”
Thanks to the external, Dr John Wood from the University of Essex, the internal Dr Bashir Al-Diri and the viva chair, Dr Kun Guo.
Congratulations and Well done.
All colleagues are invited to join Amjad on celebrating his achievement, tomorrow (Thursday 28th Feb) at 12:00noon, in our meeting room MC3108, with some drinks and light refreshments available.
New Journal paper accepted for publishing in the Journal of “Multimedia Tools and Applications“.
The paper title is “A Framework for Automatic Semantic Video Annotation utilising Similarity and Commonsense Knowledgebases”
Abstract:
The rapidly increasing quantity of publicly available videos has driven research into developing automatic tools for indexing, rating, searching and retrieval. Textual semantic representations, such as tagging, labelling and annotation, are often important factors in the process of indexing any video, because of their user-friendly way of representing the semantics appropriate for search and retrieval. Ideally, this annotation should be inspired by the human cognitive way of perceiving and of describing videos. The difference between the low-level visual contents and the corresponding human perception is referred to as the ‘semantic gap’. Tackling this gap is even harder in the case of unconstrained videos, mainly due to the lack of any previous information about the analyzed video on the one hand, and the huge amount of generic knowledge required on the other.
This paper introduces a framework for the Automatic Semantic Annotation of unconstrained videos. The proposed framework utilizes two non-domain-specific layers: low-level visual similarity matching, and an annotation analysis that employs commonsense knowledgebases. Commonsense ontology is created by incorporating multiple-structured semantic relationships. Experiments and black-box tests are carried out on standard video databases for
action recognition and video information retrieval. White-box tests examine the performance of the individual intermediate layers of the framework, and the evaluation of the results and the statistical analysis show that integrating visual similarity matching with commonsense semantic relationships provides an effective approach to automated video annotation.
Three members of the Lincoln School of Computer Science, and the DCAPI group, have attended the Vision & Language (V&L) Network workshop, 13-14th Dec. 2012 in Sheffield, UK.
Amr Ahmed, Amjad Al-tadmri and Deema AbdalHafeth attended the event, where Amjad and Deema delivered 2 oral presentations and 2 posters about their research work:
1. VisualNet: Semantic Commonsense Knowledgebase for Visual Applications
2.Investigating text analysis of user-generated contents for health related applications
Amjad Altadmri and Amr Ahmed around their poster at the Vision & Language Net workshop, 13-14th Dec 2012, Sheffield, UK.Deema AbdalHafeth and Amr Ahmed at the Vision & Language Net workshop, 13-14th Dec 2012, Sheffield, UK.
The event included tutorial sessions (Vision for language people, and language for vision people). We had an increased presence this year.
Clinical reports includes valuable medical-related information in free-form text which can be extremely useful in aiding/providing better patient care. Text analysis techniques have demonstrated the potential to unlock such information from text. I2b2* designed a smoking challenge requiring the automatic classification of patients in relation to smoking status, based on clinical reports (Uzuner Ö et al,2008) . This was motivated by the benefits that such classification and similar extractions can be useful in further studies/research, e.g. asthma studies.
Aim & Motivation
Our aim is to investigate the potential of achieving similar results by analysing the increasing and widely available/accessible online user-generated contents (UGC), e.g. forums. This is motivated by the fact that clinical reports are not widely available and has a long and rigorous process to approve any access.
We also aimed at investigating appropriate compact feature sets that facilitate further level of studies; e.g. Psycholinguistics, as explained later.
Methodology
•Data collected, systematically and with set criteria, from web forums.
•Some properties of the text, for forum data and clinical reports, were extracted to compare the writing style in clinical and forum (shown to the left and below).
•Machine learning (Support Vector Machine) classifier model was built from the collected data, using a baseline feature sets (as per the I2B2 challenge), for each data set (clinical and forum)
•Another model was built using a new feature set LIWC (Linguistic Inquiry and Word Count) + POS (Part of Speech) , for each data set (clinical and forum).
•Smoking status classification accuracy was calculated for each of the above models on each dataset.
Results
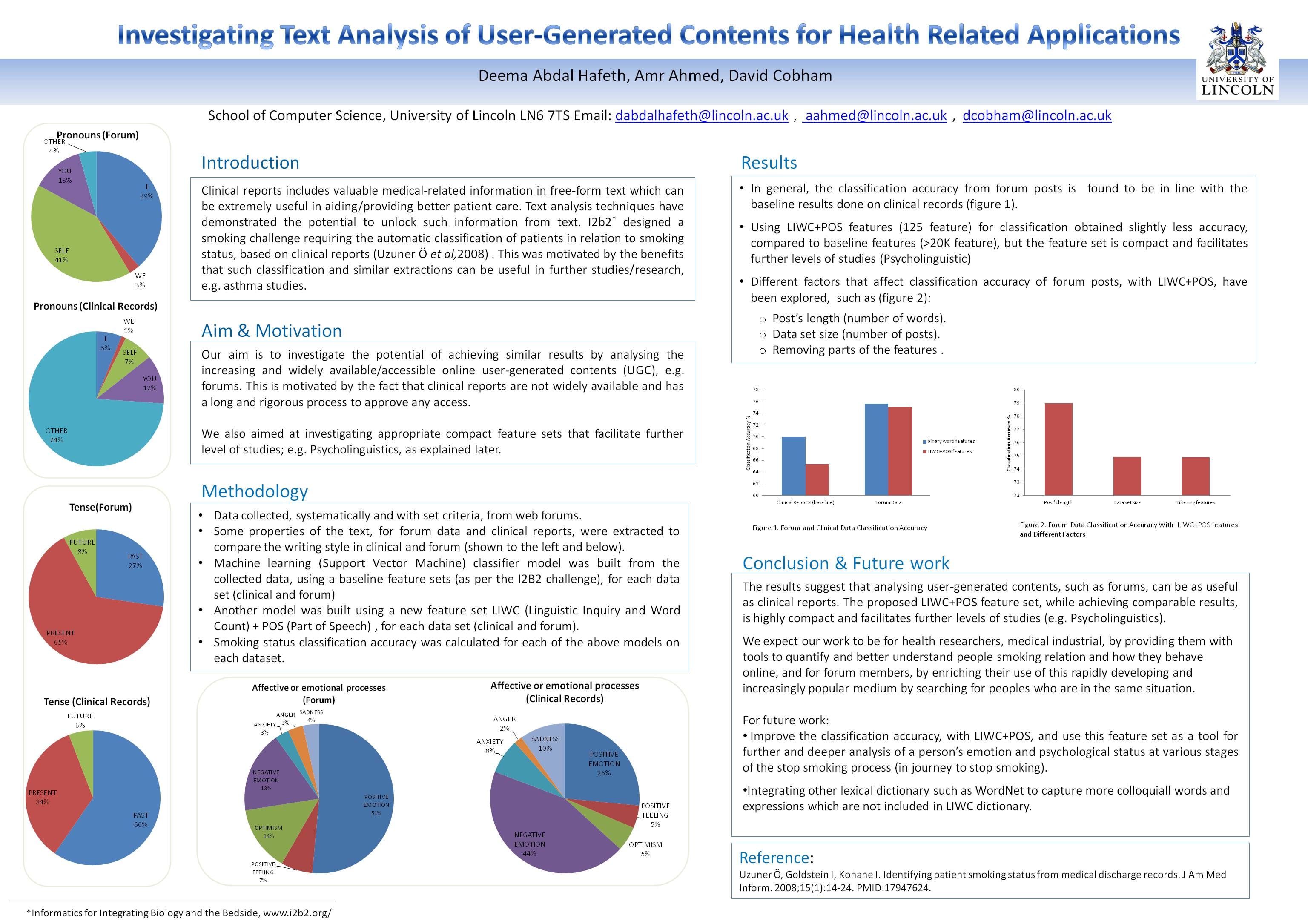
•In general, the classification accuracy from forum posts is found to be in line with the baseline results done on clinical records (figure 1).
•
•Using LIWC+POS features (125 feature) for classification obtained slightly less accuracy, compared to baseline features (>20K feature), but the feature set is compact and facilitates further levels of studies (Psycholinguistic)
•
•Different factors that affect classification accuracy of forum posts, with LIWC+POS, have been explored, such as (figure 2):
o Post’s length (number of words).
o Data set size (number of posts).
o Removing parts of the features .
Conclusion & Future work
The results suggest that analysing user-generated contents, such as forums, can be as useful as clinical reports. The proposed LIWC+POS feature set, while achieving comparable results, is highly compact and facilitates further levels of studies (e.g. Psycholinguistics).
We expect our work to be for health researchers, medical industrial, by providing them with tools to quantify and better understand people smoking relation and how they behave online, and for forum members, by enriching their use of this rapidly developing and increasingly popular medium by searching for peoples who are in the same situation.
For future work:
• Improve the classification accuracy, with LIWC+POS, and use this feature set as a tool for further and deeper analysis of a person’s emotion and psychological status at various stages of the stop smoking process (in journey to stop smoking).
•Integrating other lexical dictionary such as WordNet to capture more colloquiall words and expressions which are not included in LIWC dictionary.
Reference:
Uzuner Ö, Goldstein I, Kohane I. Identifying patient smoking status from medical discharge records. J Am Med Inform. 2008;15(1):14-24. PMID:17947624.
We just had 2 posters and oral presentations accepted for the coming Vision & Language (V&L) Network workshop, 13-14th Dec. 2012 in Sheffield, UK. This is a good representation from Lincoln (and from the DCAPI group).
1. VisualNet: Semantic Commonsense Knowledgebase for Visual Applications
2.Investigating text analysis of user-generated contents for health related applications
This is the Eid Day (Celebrating the end of the Holy Month of Ramadan). Memebers of the Egyptian Paralympic Teams have joined the Lincoln community in the Eid Prayer, before heading to their training venues.
Eid Prayer: Members of the Egyptian Paralympics Team joined the Lincoln’s community for Eid prayer and celebration, on their first day of the pre-games training camp.
Then, the teams split:
* Sitting Volly Ball and Table Tennis teams gone to their training venue, the Sports Centre at the University of Lincoln.
* Powerlifting team gone to their training venue, Louth.
* Athletes team gone to their training venue, Boston.
Amr joined the Athletes in Boston.
The Egyptian Paralympics Atheletics Team going to their first training session in Boston. Dr Hamdy (Head Coach, middle), Eng. Mohamed Eassa (Coach, left) Captin Hosam (Assistant Coach, middle, 2nd row), Captin Mostafa (Athlete, left, 2nd row) and Dr Amr Ahmed (right) accompanying the team.
The Egyptian Paralympic Athletics team having lunch in Boston, following their first training session.
After the first training session, all teams returned back to the hotel, where the official welcome event was held, with the Deputy Mayor, Mayor of Boston, Councilour of East Lindsey, and the Egyptian and Arab communities.
Members of the Egyptian Paralympic Teams, Egyptian & Arab Community, and the Deputy Mayor, during the official welcome event of the pre-games training camp in Lincoln
Members of the Egyptian Paralympic Teams, Egyptian & Arab Community, and the Deputy Mayor, during the official welcome event of the pre-games training camp in Lincoln
Prof. Mohsen El-Mahdy, Chief De Mission, presented the Deputy Mayor with the Egyptian flag and decorated him with the Egyptian Paralympics Committee badge. Prof. Mohsen has also thank the Egyptian and Arab families and presented the Egyptian flagto Dr Amr Ahmed and decorated him with the Egyptian Paralympics Committee badge, as an appreciation for all the voluntary effort in preparation for this training camp.
Prof. Mohsen El-Mahdy (Chief De Mission) presenting the Egyptian flag to the Deputy Mayor of Lincoln, during the Official Welcome Event for the Egyptian Paralympic Teams at the beginning of their pre-games training camp in Lincolnshire.
Amr (Standing, right) with other guests including the Mayor of Boston (Sitting) and Mr Robin Wright (Left, the Manager of the University’s Sports Centre)Amr (right) holding the Olympic Torsh, with Roy Wright (left) the Olympic Torsh holder who came to welcome the Egyptian Paralympic Team in Lincoln and kindly brought the torsh with him. In the mean time, BBC Look North are recording in the back.
Then, the volly ball and table tennis teams had another training session at the sports centre.
Finally, the day is concluded by a Dinner with the Arabic community with traditional food.